黃淑君2024-07-05 10:29

![]()

今年以來,針對人工智能(AI)給人類帶來潛在危機(jī)的話題一直爭議不斷,更有多領(lǐng)域權(quán)威專家聯(lián)合發(fā)起“人工智能或?qū)⒅氯祟悳缃^”的風(fēng)險(xiǎn)警告聲明。而包括近期好萊塢爆發(fā)“抵制AI侵入”的大罷工在內(nèi),越來越多人擔(dān)憂AI的崛起和發(fā)展將影響人類社會(huì),特別是在多個(gè)領(lǐng)域中取代人工。不過,根據(jù)一項(xiàng)最新發(fā)布的研究結(jié)果顯示,起碼在幽默感方面,目前的人工智能似乎還比不上人類。
這一最新研究論文發(fā)表在上月剛結(jié)束的第61屆計(jì)算語言學(xué)協(xié)會(huì)年會(huì)(ACL2023)官方收錄的論文集(第一卷:長論文)中,也是本屆ACL獲獎(jiǎng)的三篇年度最佳論文之一。ACL是自然語言處理領(lǐng)域最具影響力的國際學(xué)術(shù)會(huì)議。該得獎(jiǎng)?wù)撐念}為“Do Androids Laugh at Electric Sheep? Humor ‘Understanding’ Benchmarks from The New Yorker Caption Contest”(譯:機(jī)器人會(huì)笑話電子羊嗎?基于《紐約客》漫畫標(biāo)題比賽的幽默“理解”基準(zhǔn))。
目前,基于大型神經(jīng)網(wǎng)絡(luò)(人工智能的一種形式)的發(fā)展,短時(shí)間內(nèi)生成上千甚至上萬條笑話是可以實(shí)現(xiàn)的。而本篇論文探討的是,這么“會(huì)說笑話”的人工智能是否真正理解得了其中的幽默。研究人員利用美國知識(shí)、文藝類綜合雜志《紐約客》漫畫標(biāo)題比賽(The New Yorker Cartoon Caption Contest)中數(shù)百個(gè)參賽作品作為測試數(shù)據(jù),以此向人工智能模型發(fā)起三項(xiàng)任務(wù)挑戰(zhàn):將笑話與漫畫進(jìn)行匹配(匹配任務(wù),Matching),識(shí)別獲勝標(biāo)題(質(zhì)量評估任務(wù),Quality Ranking),以及解釋為什么獲勝標(biāo)題是有趣的(解釋任務(wù) Explanation Generation)。

本次論文的主要作者、來自艾倫人工智能研究所(Allen Institute for AI,AI2)的研究科學(xué)家Jack Hessel博士指出,人類挑戰(zhàn)人工智能模式的理解方式是為它們建立測試,無論是選答式測驗(yàn)(multiple choice test)還是其他帶精度的評估。如果特定模型最終在測試得分中超越了人類,人們還是會(huì)想“好吧,這是否意味著它真正理解呢?”Hessel博士表示,機(jī)器不能做到“真正的理解”的說法是站得住腳的,因?yàn)槔斫鈴膩矶际侨祟惖氖虑椤!暗珶o論機(jī)器是否理解,它們在這些任務(wù)中的表現(xiàn)仍然令人印象深刻。”
研究數(shù)據(jù)選取自《紐約客》14年間超過700場的漫畫標(biāo)題比賽,包括每一場比賽的一幅未配文漫畫、比賽入圍作品以及由《紐約客》編輯評選出的三名候選作品。Hessel博士表示,《紐約客》作品有趣的地方是,圖片與標(biāo)題之間的關(guān)系是間接、幽默,且引用了許多現(xiàn)實(shí)生活中的實(shí)例和規(guī)范,這也使得“理解”在此次研究任務(wù)中更為復(fù)雜。

基于此,如研究團(tuán)隊(duì)所指,三項(xiàng)任務(wù)的復(fù)雜程度是逐漸進(jìn)階的,其關(guān)鍵在于測試AI能否理解圖像與文本標(biāo)題之間的復(fù)雜性,以及那些經(jīng)常基于人類經(jīng)驗(yàn)和文化的間接且有趣的隱喻。研究人員還使用了多模態(tài)和單一語言兩種模式進(jìn)行測試,前者基于像素(計(jì)算機(jī)視覺),直接對漫畫圖像開啟挑戰(zhàn);而后者則基于描述即采用對視覺場景進(jìn)行多方面的描述,以模擬人類水平的視覺理解。
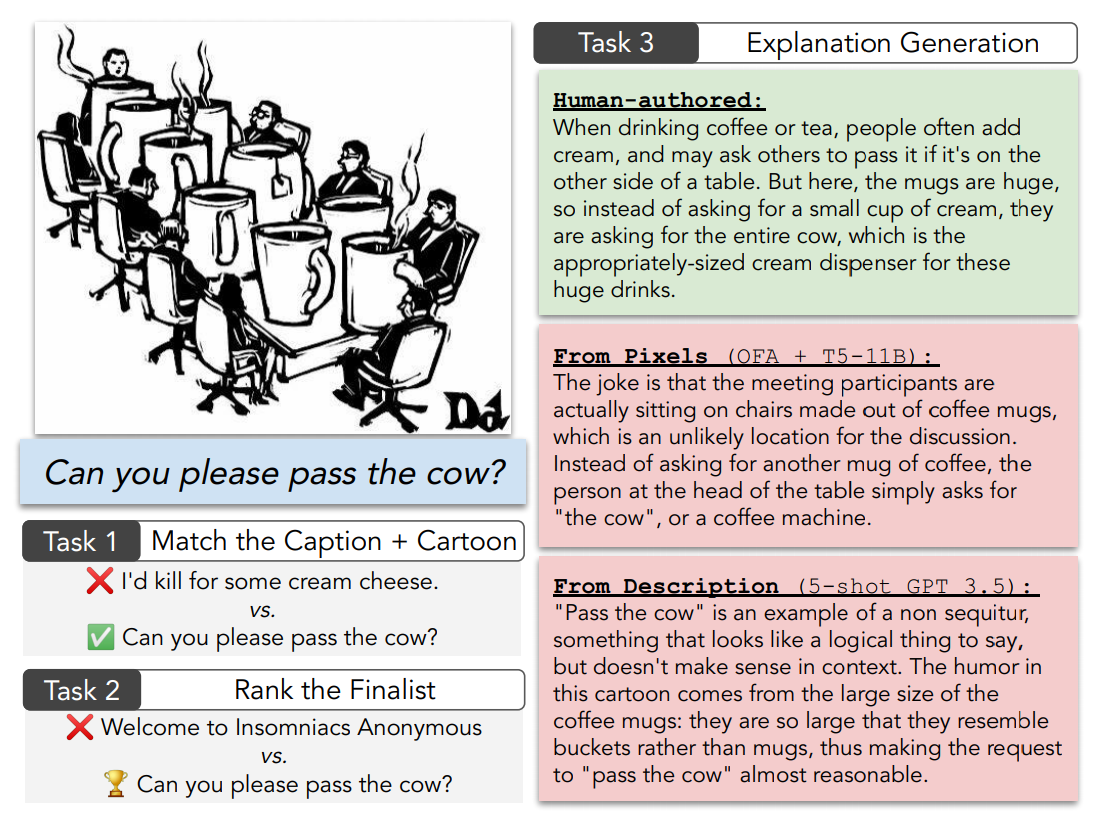
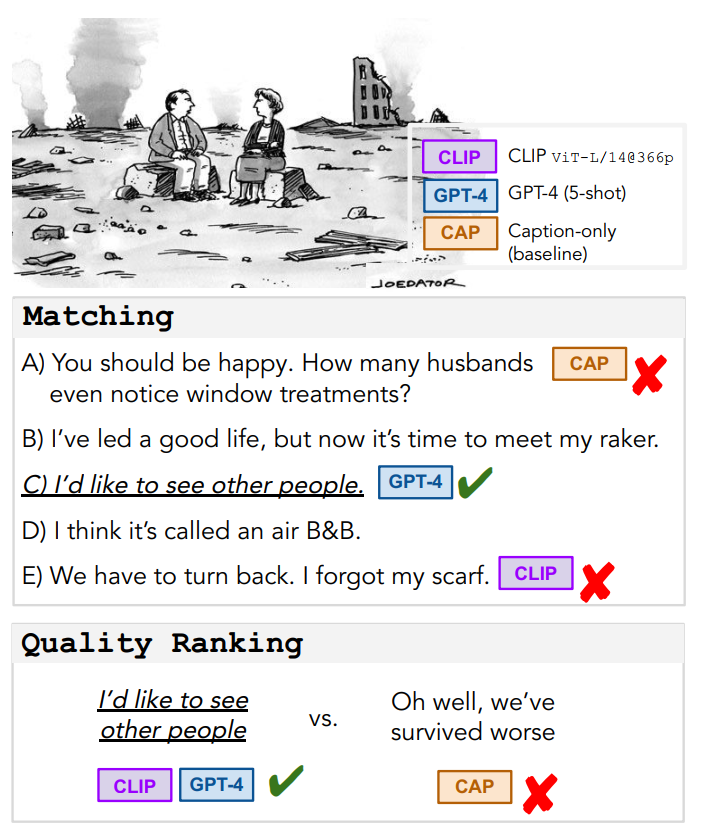
在研究過程中,匹配任務(wù)需要AI從所有比賽的獲勝標(biāo)題中,選擇出對應(yīng)特定比賽的正確獲勝標(biāo)題。質(zhì)量評估任務(wù)中需要AI在同一比賽的入圍作品中識(shí)別出候選名單和非候選名單。而解釋任務(wù)則需要AI自由生成文本,說明高質(zhì)量文本(獲勝標(biāo)題)是如何與漫畫相關(guān)的。但研究發(fā)現(xiàn),兩種類型的模型均在挑戰(zhàn)所有三個(gè)任務(wù)上存在困難,且AI與人類之間的差距頗大。
例如,在匹配任務(wù)中,研究期間最好的多模態(tài)模型(62%)的性能比人類(94%)低30個(gè)精度點(diǎn);即使提供了真實(shí)的視覺場景描述,人類撰寫的解釋在超過2/3的任務(wù)表現(xiàn)中也要優(yōu)于機(jī)器(基于GPT-4模型的few-shot多樣本模板)。換言之,就本次研究表明,即使已經(jīng)有像ChatGPT這類先進(jìn)的人工智能模型不斷進(jìn)步并逐漸縮小差距,但在理解幽默這一方面,就目前來說,人類明顯要優(yōu)于人工智能。
面對這一結(jié)果,研究人員在論文中寫道,“雖然AI可能還不太能理解所謂的幽默,但它可能是幽默家們用來集思廣益的協(xié)作工具。”事實(shí)上,AI浪潮已是大勢所趨,無疑會(huì)給人類社會(huì)帶來一些顛覆性的影響。尤其自去年底ChatGPT此類生成式人工智能掀起“全民AI熱”,急速激發(fā)了各類創(chuàng)作者之間的爭論:有人將其視為一種威脅,會(huì)將人類取而代之;但也有人認(rèn)為是一種協(xié)作手段,以期增強(qiáng)創(chuàng)造力。
總部位于紐約的人工智能初創(chuàng)公司Type首席執(zhí)行官Stew Fortier認(rèn)為,人工智能確實(shí)存在兩極化的本質(zhì),但他本人對內(nèi)容創(chuàng)作中人工智能的看法非常明確,即人工智能是一種增強(qiáng)輔助工具而非“人類的替代品”。該公司主打人工智能文檔編輯輔助工具Type.ai。
“一個(gè)常見的誤解,特別是關(guān)于人工智能方面,是認(rèn)為它是一種旨在取代人類的工具”,F(xiàn)ortier強(qiáng)調(diào)道,但基于他的實(shí)踐經(jīng)驗(yàn),人工智能是一種“半意識(shí)狀態(tài)下的頭腦風(fēng)暴助手”,是幫助創(chuàng)作者更有效地表達(dá)想法的第二個(gè)大腦。他希望人們在面對人工智能時(shí),“將替代的恐懼轉(zhuǎn)變?yōu)樵鰪?qiáng)的興奮”。
與此同時(shí),一些大型創(chuàng)作平臺(tái)也通過發(fā)布新條例,在肯定人類創(chuàng)作者的重要性同時(shí),鼓勵(lì)其無需完全抗拒人工智能。今年6月,美國錄音學(xué)院(The Recording Academy)宣布對格蘭美獎(jiǎng)進(jìn)行一系列規(guī)則修訂,其中包括允許音樂作品中使用人工智能進(jìn)行創(chuàng)作,但明確只有人工創(chuàng)作者部分才能得獎(jiǎng),例如若一首歌曲中人類負(fù)責(zé)編曲作詞、人工智能負(fù)責(zé)主要演唱獻(xiàn)聲,則允許其在作曲類而非演唱類中參賽;同時(shí)還再三強(qiáng)調(diào),“不包含人類創(chuàng)作者的作品不符合任何類別的參賽資格”。
對此,美國錄音學(xué)院首席執(zhí)行官及主席Harvey Mason Jr.表示,只要人類創(chuàng)作者獻(xiàn)出了最低程度上的貢獻(xiàn),就都是有意義的行為,他們就會(huì)允許擁有提名或得獎(jiǎng)的資格。“我們不希望看到技術(shù)取代人類的創(chuàng)造力。我們希望的是確保技術(shù)能夠讓人類的創(chuàng)造力得到增強(qiáng)、美化或增色。這就是為什么我們在(接下來的)這次頒獎(jiǎng)周期中采取了這一特殊立場(即允許涉及人工智能創(chuàng)作的歌曲擁有參賽資格)。”
“對于人工智能的恐懼,不僅僅是因?yàn)槿祟惖氖褂梅绞剑且驗(yàn)檫@讓人想起普羅米修斯將火作為禮物帶給人類之前,人類在面對閃電時(shí),那種對于未知的恐懼。”意大利奢侈品牌創(chuàng)始人Brunello Cucinelli在近日致公眾的《關(guān)于人工智能與人類智慧的一封信》中寫道,“我很難想象一個(gè)機(jī)器人或人工智能系統(tǒng)能夠感受到真正的情感或深刻的感受;機(jī)器人能夠仰望天空,或者體會(huì)到情感,并從自己的眼中涌出真實(shí)的淚水嗎?”感受人類真實(shí)的情感,充滿幽默感,至少現(xiàn)在人工智能還遠(yuǎn)不似人類。
文章來源:財(cái)聯(lián)社
作者:黃淑君
 京公網(wǎng)安備 11010802028547號(hào)
京公網(wǎng)安備 11010802028547號(hào)
 購物車
購物車






