2024-05-29 17:11

![]()

【經(jīng)觀講堂】系經(jīng)濟(jì)觀察報(bào)社年度培訓(xùn)項(xiàng)目,邀請(qǐng)來自經(jīng)濟(jì)、傳媒、科學(xué)、文化、法律、商業(yè)等領(lǐng)域知名人士講授常識(shí)與新知,分享經(jīng)典和創(chuàng)新,是助力提升經(jīng)觀內(nèi)容品質(zhì)和傳播影響的開放型課堂。
竇德景是北電數(shù)智首席科學(xué)家,復(fù)旦大學(xué)特聘教授,清華大學(xué)電子工程系兼職教授,此前曾擔(dān)任波士頓咨詢公司(BCG)合伙人、副總裁、中國區(qū)首席數(shù)據(jù)科學(xué)家,百度研究院大數(shù)據(jù)實(shí)驗(yàn)室和商業(yè)智能實(shí)驗(yàn)室主任,美國俄勒岡大學(xué)計(jì)算機(jī)和信息科學(xué)系教授。他的研究領(lǐng)域包括人工智能、數(shù)據(jù)挖掘、數(shù)據(jù)整合、自然語言處理和健康信息學(xué)等。
本文根據(jù)竇德景在【經(jīng)觀講堂】上的發(fā)言整理。
非常高興能夠來到《經(jīng)濟(jì)觀察報(bào)》做這樣一個(gè)分享,我把講的內(nèi)容分成兩部分,一部分是前大模型時(shí)代,基本上是基于2022年之前的工作;一部分是大模型時(shí)代,也就是2022年之后發(fā)生的事情。在前大模型時(shí)代,大數(shù)據(jù)已經(jīng)很火了,深度學(xué)習(xí)已經(jīng)出來了,大模型也是深度學(xué)習(xí)技術(shù)發(fā)展的最新產(chǎn)物。當(dāng)然我相信,除了大模型,以后還會(huì)有更強(qiáng)大、更先進(jìn)的新的人工智能(AI)算法和模型出來。大模型就是現(xiàn)在最好的AI技術(shù)。
我給大家講一點(diǎn)科普,也是給前大模型時(shí)代的AI正名。大模型出來了,前面的工作就沒有意義了嗎?不是這樣的,其實(shí)前面的AI現(xiàn)在也還在用。而且很多時(shí)候,作為一家公司也好,作為一個(gè)政府組織也好,你可能沒有那么多的成本直接上大模型。這些比較傳統(tǒng)的、比較簡單的AI,其實(shí)也可以用。
AI概念是如何出現(xiàn)的
那么我給AI先做一點(diǎn)簡介。《人工智能:一種現(xiàn)代方法》(Artificial Intelligence: A Modern Approach)這本書,是斯圖爾特·羅素(Stuart Russell)和彼得·諾維格(Peter Norvig)合寫的,羅素是加州大學(xué)伯克利分校的教授,諾維格一直在谷歌工作。

《人工智能:一種現(xiàn)代方法》第三版和第四版的封面
大家一看就知道,這本書的封面是個(gè)國際象棋盤。如果你對(duì)AI的歷史有了解的話,你會(huì)知道,這是因?yàn)?997年IBM的深藍(lán)計(jì)算機(jī)在國際象棋上贏了加里·卡斯帕羅夫(Garry Kasparov)。這個(gè)封面是這本書的第三版,那時(shí)還沒有第四版。2019年,我最后一次在俄勒岡大學(xué)教AI的時(shí)候,跟學(xué)生開玩笑,說你們可以預(yù)測一下第四版應(yīng)該是什么樣的封面。有的學(xué)生就猜到了,說第四版的封面應(yīng)該是一個(gè)圍棋盤。第四版在2020年出來了,封面其實(shí)也還是一個(gè)國際象棋盤,但是它把封面上的一位科學(xué)家換成了圍棋盤。但我覺得第四版的封面應(yīng)該對(duì)圍棋大書特書,好好講講圍棋對(duì)AI的貢獻(xiàn)。
在AI的概念上,我一定要給AI正名。因?yàn)槿斯ぶ悄埽ˋrtificial Intelligence)這個(gè)英語單詞的出現(xiàn),是在1956年的達(dá)特茅斯會(huì)議上,由約翰·麥卡錫(John McCarthy)和馬文·明斯基(Marvin Minsky)促成的。所以AI這個(gè)詞是1956年出來的,它絕對(duì)比2022年出來的大模型要早得多,大家一定不要認(rèn)為是因?yàn)橛写竽P筒庞蠥I的。
AI這個(gè)概念出現(xiàn)的時(shí)間,甚至比1956年還要早,因?yàn)?950年艾倫·圖靈(Alan Turing)在圖靈測試中就提出了這樣一個(gè)概念,而且他用的詞叫做機(jī)器智能(Machine Intelligence)。到底人工智能和機(jī)器智能哪個(gè)詞更合適呢?我覺得都行。從技術(shù)角度來說,我覺得機(jī)器智能更合適,圖靈希望機(jī)器擁有人的智能,但是從推廣的角度來說,普通老百姓可能不太能夠接受機(jī)器智能這個(gè)詞,所以麥卡錫就創(chuàng)造了人工智能這個(gè)詞。在英語里面,Artificial這個(gè)詞既有人工的概念,又代表人造的東西。人工智能這個(gè)詞,比圖靈最早用的機(jī)器智能更受歡迎,所以后來大家都用人工智能了。
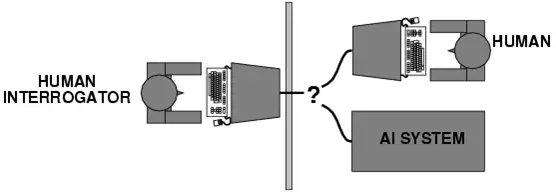
圖靈測試示意圖
為什么說圖靈是AI的鼻祖?因?yàn)樗?950年就提出了這個(gè)概念,他覺得50年以后,機(jī)器在5分鐘內(nèi)有30%的可能性可以騙過人類。比如說做一個(gè)測試,圖中左邊是一位人類測試官,他來判斷圖中右邊哪個(gè)是人、哪臺(tái)是機(jī)器。其實(shí)在50年以后的2000年,我們基本上認(rèn)為是沒有機(jī)器能通過圖靈測試的。但是從2000年開始,特別到了2010年深度學(xué)習(xí)出現(xiàn)以后,2022年大模型出來以后,我覺得AI的發(fā)展快了很多。現(xiàn)在我們基本認(rèn)為,假如用比較原始的圖靈測試的條件做測試的話,現(xiàn)在的GPT-4(美國AI公司OpenAI研發(fā)的大模型)應(yīng)該就可以騙過人了。
因?yàn)楦鞣N各樣的限制條件,最早圖靈提出圖靈測試的時(shí)候,通訊只是靠兩根線連著。但是如果你想把中間的隔板去掉,造一臺(tái)能夠真的騙過人的機(jī)器,你得希望這臺(tái)機(jī)器長得就像真人,這還是很困難的,我覺得可能還要再過幾十年才能達(dá)到這個(gè)要求。但是圖靈測試基本上比較早地就給大家指明了一個(gè)方向,我們要做一個(gè)AI,應(yīng)該要做到什么樣?GPT大模型可以產(chǎn)生文字、聲音、視頻,我覺得它已經(jīng)比較完整了。但是你真要和它對(duì)話,聊久了,GPT也會(huì)露餡。因?yàn)楫?dāng)時(shí)圖靈也說了,給5分鐘的時(shí)間,看看機(jī)器能不能騙過人類。我覺得真要做這種測試,應(yīng)該雙盲的。它不能假定,像圖中的圖靈測試一樣,隔板右邊一定是一臺(tái)機(jī)器和一個(gè)人。它不應(yīng)該告訴你有幾臺(tái)機(jī)器、幾個(gè)人,讓人類測試官自己判斷就好了。我覺得這是圖靈測試后面可以再改進(jìn)的地方。
深度學(xué)習(xí)技術(shù)在棋類游戲中發(fā)展
那么為什么第四版教科書的封面上出現(xiàn)了圍棋?1997年深藍(lán)贏了卡斯帕羅夫之后,《紐約時(shí)報(bào)》想找一位做AI的專家,來評(píng)論一下這個(gè)成果怎么樣。我的導(dǎo)師德魯·麥狄蒙(Drew McDermott)當(dāng)時(shí)是耶魯大學(xué)計(jì)算機(jī)系主任,他告訴《紐約時(shí)報(bào)》的第一句話就是,這個(gè)東西不是AI。因?yàn)樯钏{(lán)下國際象棋,基本上就是通過并行計(jì)算做一個(gè)遍歷搜索。因?yàn)閲H象棋才32個(gè)位置,只要你算力足夠的話,很容易把所有的步子都算一遍,至少IBM那個(gè)時(shí)候就做到了,機(jī)器基本上輸不了。
但是用這個(gè)辦法為什么下不了圍棋呢?因?yàn)閲鍙牡谝徊介_始,理論上是361個(gè)點(diǎn),你都可以選。然后第二步、第三步,你可以在360個(gè)點(diǎn)、359個(gè)點(diǎn)里面選。這樣對(duì)一個(gè)程序來說,宇宙里面所有分子的數(shù)量,都不夠用來表示所有的可能性,所以沒法用遍歷搜索的方法下圍棋,機(jī)器在下圍棋方面一直是不行的。直到2016年出現(xiàn)了突破,它不是靠遍歷搜索來決定到底應(yīng)該走哪一步。我們看到圍棋的復(fù)雜度,如果你把它做成一個(gè)樹狀結(jié)構(gòu)來搜索的話,那棵樹太大了,又大又深,你沒法全部把它遍歷。
所以Deepmind(谷歌旗下的AI公司)當(dāng)時(shí)就用到了卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Network),它把國際象棋上每個(gè)點(diǎn)的可能的贏率都算一下,如果你走這個(gè)地方,你贏的可能性有多大,這叫估值網(wǎng)絡(luò)(Value Network)。圍棋盤上有360個(gè)空的點(diǎn),你還是能算出來哪個(gè)點(diǎn)贏的可能性最大,但是你選的這個(gè)點(diǎn)贏率最大,并不等于這個(gè)點(diǎn)是最后走下來最合適的點(diǎn)。所以它有另外一個(gè)網(wǎng)絡(luò),叫策略網(wǎng)絡(luò)(Policy Network),就是我一步一步走,它也可以算三十幾步,就跟國際象棋的三十幾步差不多,基本上就用三十幾步的路徑來算一下哪個(gè)路徑最合適。這兩個(gè)網(wǎng)絡(luò)都是神經(jīng)網(wǎng)絡(luò)(Neural Network),把兩個(gè)網(wǎng)絡(luò)算的內(nèi)容加在一起,一個(gè)是棋盤上某一個(gè)單獨(dú)的點(diǎn)的最大贏率,另外一個(gè)是走十幾步、二十幾步或者三十幾步,哪一條路徑最好。在人類的圍棋九段高手的腦袋里面,是可以看十幾步的,但是三十幾步,他們看不到。所以后來機(jī)器就完全比人類強(qiáng)了,這是當(dāng)時(shí)的一個(gè)突破。
但是它有個(gè)特點(diǎn),2016年的AlphaGo(Deepmind研發(fā)的AI程序)是用人類高手的100萬盤棋譜訓(xùn)練出來的,所以它就通過100萬盤棋譜計(jì)算,大家下圍棋時(shí)一般走哪一步,這個(gè)概率可以算出來。為什么李世石還贏了AlphaGo一盤棋?李世石當(dāng)時(shí)輸?shù)袅饲皟杀P棋,已經(jīng)沒有心理負(fù)擔(dān)了。在下第三盤棋的時(shí)候,他走了一個(gè)不常見的走法。AlphaGo根據(jù)高手的傳統(tǒng)走法計(jì)算怎么下棋,碰到李世石的這個(gè)走法,它就蒙了,不知道應(yīng)該怎么應(yīng)對(duì),所以說李世石還贏了一盤棋。
AlphaGo登上了《自然》(Nature)雜志封面,但是在我看來這并不是最大的成功,最大的成功反而是Deepmind后面一年的工作,就是研發(fā)出了AlphaGo Zero。AlphaGo Zero不用人類下過的棋譜做訓(xùn)練,它就設(shè)計(jì)兩個(gè)最簡單的、只知道規(guī)則的機(jī)器棋手——Alpha和Beta。圍棋規(guī)則很簡單,所以很容易在計(jì)算機(jī)里面把它們的規(guī)則定好。機(jī)器棋手是不用休息的,讓它們24小時(shí)不停地互相下,這兩個(gè)機(jī)器棋手就能不斷地提高水平。到AlphaGo Zero出來以后,它的勝率大概是AlphaGo最初版本的100倍。所以在李世石跟AlphaGo下圍棋的時(shí)候,人類還有可能贏。到了AlphaGo Zero這樣的技術(shù)水平,它跟當(dāng)時(shí)世界圍棋排名第一的柯潔下時(shí),柯潔就一點(diǎn)機(jī)會(huì)都沒有了。

2018年圖靈獎(jiǎng)得主
一般來說,圖靈獎(jiǎng)不像菲爾茲獎(jiǎng),要求40歲以下的人選才能獲獎(jiǎng)。圖靈獎(jiǎng)和諾貝爾獎(jiǎng)基本上是一種終身成就獎(jiǎng)。所以圖靈獎(jiǎng)一般會(huì)在研究者做出研究成果的很多年之后授予,作為對(duì)他的成就的承認(rèn)。但是深度學(xué)習(xí)出來以后,特別是AlphaGo、AlphaGo Zero出來以后,圖靈獎(jiǎng)很快就授予了三巨頭——約書亞·本吉奧(Yoshua Bengio)、杰弗里·辛頓(Geoffrey Hinton)和雅恩·樂昆(Yann LeCun)。人們有一個(gè)誤區(qū),認(rèn)為這三個(gè)人是AI之父,這絕對(duì)是錯(cuò)誤的,說他們是深度學(xué)習(xí)之父是對(duì)的,深度學(xué)習(xí)只是AI比較新的或者比較成功的分支。
其實(shí),圍棋是比較小眾的棋類游戲,特別是在西方世界。一般來說,就是中國、日本、韓國三個(gè)國家的人比較喜歡下圍棋。我覺得后面的這項(xiàng)工作更有意義,2020年AlphaFold2(Deepmind研發(fā)的AI程序)出來了,上個(gè)星期AlphaFold3出來了。它們基本上可以開展對(duì)原來技術(shù)水平來說很復(fù)雜的科學(xué)工作,比如蛋白質(zhì)結(jié)構(gòu)預(yù)測。因?yàn)橐粋€(gè)氨基酸的序列,你可以折疊成各種各樣的蛋白結(jié)構(gòu),AlphaFold可以算出來哪幾個(gè)結(jié)構(gòu)的可能性更大。當(dāng)然它也不能根據(jù)一個(gè)序列(sequence)推斷出,一定就是這樣一個(gè)結(jié)構(gòu),它給出的是概率,但是它的預(yù)測準(zhǔn)確度當(dāng)時(shí)已經(jīng)超過80%了。對(duì)人類來說,工作就變得很簡單,你可以先用機(jī)器幫你算一下,然后針對(duì)比較可能的那幾個(gè)結(jié)構(gòu),再去做濕實(shí)驗(yàn),這大大節(jié)省了時(shí)間和財(cái)力、物力。
另外,從機(jī)器人的角度來說,波士頓動(dòng)力應(yīng)該是全球做得最好的,因?yàn)锳I的發(fā)展必然會(huì)帶動(dòng)機(jī)器人的進(jìn)步。現(xiàn)在假如你把大模型或者深度學(xué)習(xí)的東西,加到機(jī)器人里面,它的整個(gè)動(dòng)作都會(huì)比原來的更精確。
大數(shù)據(jù)的4個(gè)特征
大數(shù)據(jù)是在大模型之前比較火的一個(gè)概念。大家可能都理解,因?yàn)樘貏e是在我們這個(gè)時(shí)代,經(jīng)歷了互聯(lián)網(wǎng)、iPhone,應(yīng)該說數(shù)據(jù)的產(chǎn)生和處理比原來多得多。
大數(shù)據(jù)基本上有3個(gè)特征,叫做3個(gè)V。一個(gè)是規(guī)模性(volume),就是數(shù)據(jù)量非常大。從數(shù)據(jù)的增長速度來看,大模型的參數(shù)都是這樣的,不是線性的增長,而是指數(shù)級(jí)的增長。另一個(gè)是速度性(Velocity),處理數(shù)據(jù)時(shí)要快速地解決。我舉個(gè)例子,你如果要盡快地完成促銷,捕捉到用戶的信息后,要趕快行動(dòng)起來,不然用戶的興趣會(huì)發(fā)生變化。你要是隔上一星期、兩星期,才知道用戶對(duì)這個(gè)東西感興趣,這時(shí)用戶可能已經(jīng)不感興趣了。像醫(yī)療健康這類行業(yè),你發(fā)現(xiàn)一些異常,要趕快處理。還有一個(gè)是多樣性(Variety),一定要把不同種類的數(shù)據(jù)放在一起處理,這樣才有意義,才能更好地做決定。數(shù)據(jù)種類是各種各樣的,不僅有文本、序列,還有圖片、表格,它們都在一起,這也就是所謂的多模態(tài),跟大模型其實(shí)也相關(guān)。
原來大數(shù)據(jù)的特征肯定是這3個(gè)V,現(xiàn)在我對(duì)第四個(gè)V——真實(shí)性(Veracity)特別感興趣。特別是在大模型出現(xiàn)以后,數(shù)據(jù)越來越不可信了。所以數(shù)據(jù)的準(zhǔn)確度、一致性、真實(shí)性都成了問題。在這種情況下再說大數(shù)據(jù),一定要強(qiáng)調(diào)真實(shí)性。
大模型的參數(shù)規(guī)模呈指數(shù)級(jí)增長
接下來我介紹大模型時(shí)代。大家都知道,特別是在2022年底,大模型的關(guān)注度增長非常快。因?yàn)槟阌盟阉饕娴臅r(shí)候,可以看出一個(gè)詞的關(guān)注度。另外一點(diǎn),ChatGPT(OpenAI研發(fā)的聊天機(jī)器人程序)的用戶數(shù)5天達(dá)到100萬,更夸張的是,不到兩個(gè)月,它的用戶數(shù)達(dá)到1億。所以它是歷史上用戶數(shù)最快到達(dá)1億的App。我可以說這肯定是前無古人的,但絕對(duì)不是后無來者,我相信下一個(gè)爆款A(yù)pp的用戶數(shù)應(yīng)該會(huì)比ChatGPT更快地達(dá)到1億。因?yàn)镃hatGPT出現(xiàn)以后,大家對(duì)AI的接受速度快了很多,我相信下一個(gè)爆款A(yù)pp出來了,更多人會(huì)很快地去用。
我剛才給大家做了一點(diǎn)科普,AI這個(gè)詞在1956年就有了,后來出現(xiàn)專家系統(tǒng)(Expert Systems)等詞。如果從參數(shù)這個(gè)角度來說,專家系統(tǒng)的參數(shù)基本是零或者比較少。深度學(xué)習(xí)的參數(shù)就比較多了。到了大模型最初的產(chǎn)品GPT-1,它的參數(shù)大概是1000萬。到了GPT-3,它的參數(shù)達(dá)到1750億,模型參數(shù)(Model Parameters)的增長曲線在這里出現(xiàn)了拐點(diǎn)。GPT-4的參數(shù)大概是1.8萬億,不到10萬億。而且模型參數(shù)的增長跟大數(shù)據(jù)一樣,它絕對(duì)不是線性增長,而是指數(shù)級(jí)的增長。
模型參數(shù)不是指有多少個(gè)神經(jīng)元,而是指有多少個(gè)神經(jīng)元之間的連接。因?yàn)橐粋€(gè)神經(jīng)元可以連很多個(gè)神經(jīng)元,所以它自然對(duì)應(yīng)著多個(gè)連接。今年年底就要出來的GPT-5,它的參數(shù)至少是5萬億至10萬億。人腦中大概有100萬億個(gè)連接。其實(shí)人腦的神經(jīng)元數(shù)量大概也就是100億個(gè),但是假如人腦中的連接,是任何一個(gè)神經(jīng)元連接任何一個(gè)神經(jīng)元,那么連接的數(shù)量就是100億個(gè)乘以100億個(gè),這個(gè)數(shù)量太大了,所以人腦中的神經(jīng)元只是和附近的一些神經(jīng)元連接,而不是和所有的連接。
從這個(gè)角度來說,我覺得大模型發(fā)展到了GPT-5,成為10萬億參數(shù)的模型,它的能力基本上跟人腦差不多了。人腦雖然有100萬億個(gè)連接,但是人類平常使用的面積大概只有十分之一,人腦很多時(shí)候都是閑的。當(dāng)然阿爾伯特·愛因斯坦(Albert Einstein)大腦的使用面積可能大一點(diǎn),普通人使用不了那么多。所以根據(jù)我的估計(jì),這條路如果走通了,這是一個(gè)模擬人或者逼近人的智力的最佳方式。10萬億參數(shù)的模型就足夠了,我們就拭目以待吧。因?yàn)樯侥?middot;奧特曼(Sam Altman)已經(jīng)在不同場合放話了,GPT-5會(huì)比GPT-4強(qiáng)太多。
Transformer算法推動(dòng)生成式AI發(fā)展
生成式AI不僅是最早的文本對(duì)話機(jī)器人,其實(shí)在圖片、視頻領(lǐng)域,現(xiàn)在也能看出來它有一個(gè)非常清楚的多模態(tài)聯(lián)系。為什么它能把這些模態(tài)的聯(lián)系建立起來?它用的算法,不僅只是文本之間相互的token(文本中的最小語義單元)的聯(lián)系,還可以把文本和圖像、文本和視頻、文本和聲音都聯(lián)系起來。2017年,其實(shí)就出現(xiàn)了現(xiàn)在大家都在談的生成式AI這個(gè)概念,但是2022年的ChatGPT真正讓大家認(rèn)識(shí)到大模型、生成式AI有這么強(qiáng)大的功能。
其實(shí)OpenAI選了一個(gè)大家都不看好的方向來突破。人們從2018年10月開始做大模型,一直沒有找到突破點(diǎn),讓大家知道這個(gè)東西有用。結(jié)果OpenAI選擇做了對(duì)話機(jī)器人(Chatbot),其實(shí)這個(gè)東西最早從20世紀(jì)50年代—60年代就開始做了。只要做AI,你就會(huì)想到去跟它對(duì)話,做智能客服什么的,但是原來做得都不太好。到了2017年,谷歌發(fā)明了一種叫Transformer的算法。我認(rèn)為發(fā)表關(guān)于Transformer論文的這些人里面,未來肯定有人拿圖靈獎(jiǎng),關(guān)鍵是這篇文章的作者名單很長,到底把獎(jiǎng)給誰是個(gè)問題。因?yàn)閳D靈獎(jiǎng)最多就給三個(gè)人,所以怎么把這幾個(gè)人挑出來,我覺得是評(píng)委會(huì)發(fā)愁的問題。
我講講Transformer的原理,我可以用它算我輸入的所有token之間的關(guān)系。我經(jīng)常舉這樣一個(gè)例子,姚明有沒有拿過奧運(yùn)獎(jiǎng)牌?姚明沒有拿過。如果我現(xiàn)在問GPT-3.5這個(gè)問題,它的回答還是錯(cuò)的,GPT-4和文心一言的回答是對(duì)的。GPT-3.5一直認(rèn)為姚明拿過奧運(yùn)獎(jiǎng)牌,這是因?yàn)槲覀冊(cè)谧瞿P皖A(yù)訓(xùn)練的時(shí)候,其實(shí)是在做完形填空。比如我把姚明、奧運(yùn)等幾個(gè)詞列出來,把中間的獎(jiǎng)牌這個(gè)詞給摳掉,讓大模型去猜,姚明到底有沒有拿過。GPT-3.5在做這個(gè)完形填空的時(shí)候,就去把姚明、籃球這些詞,跟奧運(yùn)會(huì)的金牌、銀牌、銅牌聯(lián)系起來,相當(dāng)于它算了一個(gè)概率。它用大量的語料去訓(xùn)練,就能夠把這些詞的關(guān)系給算出來。當(dāng)時(shí)我對(duì)GPT-3.5的回答也好奇,就去網(wǎng)絡(luò)上搜索姚明、奧運(yùn)、獎(jiǎng)牌這些詞,沒有任何一個(gè)網(wǎng)絡(luò)上的公開信息說,姚明拿過奧運(yùn)獎(jiǎng)牌。
那么GPT-3.5為什么這樣回答?當(dāng)它接收你的問題的時(shí)候,它先算一下哪些詞跟姚明、奧運(yùn)、獎(jiǎng)牌這幾個(gè)詞相關(guān)。跟姚明相關(guān)的詞,是籃球、NBA、選秀狀元、世界第一中鋒、國家隊(duì)主力。跟奧運(yùn)相關(guān)的詞,與姚明聯(lián)系在一起的是悉尼、雅典、北京三屆奧運(yùn)會(huì)。跟獎(jiǎng)牌相關(guān)的詞,那就是金、銀、銅三種奧運(yùn)獎(jiǎng)牌。所以這是第一輪,在它算了相關(guān)性以后,就把這些詞給找出來了。再想想這些詞之外的詞,就不一定跟姚明相關(guān)了。比如它看到偉大的籃球運(yùn)動(dòng)員、MBA選秀狀元、第一中鋒這些詞,就會(huì)想到科比·布萊恩特(Kobe Bryant)、勒布朗·詹姆斯(LeBron James)、保羅·加索爾(Pau Gasol)。GPT-3.5想到這幾個(gè)人的話,再去聯(lián)想他們參加的奧運(yùn)會(huì)、他們是否拿過奧運(yùn)獎(jiǎng)牌。他們拿過奧運(yùn)獎(jiǎng)牌的。所以,它從合理性角度計(jì)算,姚明那么偉大,偉大到和這幾個(gè)人相提并論,姚明就應(yīng)該拿過奧運(yùn)獎(jiǎng)牌。所以GPT-3.5的問題就出在這里。但是GPT-4或者文心一言就不會(huì)出現(xiàn)這種情況。這種問題是問事實(shí)、歷史的問題,不是讓它來寫一首詩、一部小說,它不需要生成內(nèi)容。它直接去搜,一搜的話就會(huì)發(fā)現(xiàn),姚明確實(shí)沒有拿過奧運(yùn)獎(jiǎng)牌。
Transformer產(chǎn)生了預(yù)訓(xùn)練語言模型。語言預(yù)訓(xùn)練能夠把關(guān)聯(lián)關(guān)系建立起來,可以完成完形填空。但是如果你要用它真正來做一些事,要用新的強(qiáng)化學(xué)習(xí)算法RLHF(Reinforcement Learning with Human Feedback,即從人類反饋中強(qiáng)化學(xué)習(xí)),用人類的反饋指導(dǎo)模型做具體的工作。因?yàn)轭A(yù)訓(xùn)練只是把一些基礎(chǔ)的知識(shí)、基本的概念給建立起來了,但它應(yīng)該做什么事,由你來告訴它。所以GPT-3.5這個(gè)模型,是基于GPT-3來訓(xùn)練它的對(duì)話的,給它一些對(duì)話的標(biāo)準(zhǔn)答案,看它答得怎么樣。它答得好,我給高分,答得差,我給低分。要不停地給它一些反饋,不斷地提高它。
生成式AI的幾個(gè)特征
生成式AI的技術(shù)突破有4點(diǎn)原因。第一是模型規(guī)模,GPT-3的參數(shù)規(guī)模是1750億,GPT-4的參數(shù)規(guī)模是1.8萬億。清華的開源模型ChatGLM,參數(shù)規(guī)模也能達(dá)到1300億。現(xiàn)在看來,基本上參數(shù)規(guī)模在千億以上的模型,性能是比較突出的。第二是訓(xùn)練數(shù)據(jù),因?yàn)樽鐾晷翁羁眨遣恍枰鰳?biāo)注的。我們把所有數(shù)據(jù)扔進(jìn)去,萬億的token也好,各種類型的數(shù)據(jù)語料也好,扔進(jìn)去讓它不停地去填空。這是一個(gè)好處,它不需要人來做標(biāo)注。第三是訓(xùn)練方法,可以把人類的反饋加進(jìn)來。第四是算力,英偉達(dá)A100顯卡和高性能并行計(jì)算平臺(tái),提供了超強(qiáng)算力支持。其實(shí)英偉達(dá)這個(gè)公司一開始不溫不火,它就是做電腦游戲需要用到的顯卡。后來,人們發(fā)現(xiàn)它的顯卡可以給深度學(xué)習(xí)模型用。特別是到了大模型時(shí)代,更是需要它的顯卡。所以英偉達(dá)是現(xiàn)在最火的公司,它的市值漲上去了。黃仁勛也成了美國工程院院士,他也在做建議,要引導(dǎo)AI的發(fā)展方向。生成式AI成就了黃仁勛。
從生成式AI的整個(gè)架構(gòu)來看,在硬件設(shè)施也就是算力層面,英偉達(dá)的市場份額可能占了95%,其他廠商包括谷歌、英特爾、華為、百度昆侖芯等,最近好像AMD也準(zhǔn)備做AI芯片。硬件設(shè)施層面之上是云平臺(tái),因?yàn)檫@些算力最后要放在云上面來計(jì)算。云平臺(tái)層面之上是模型,模型又分為閉源模型和開源模型。模型層面之上是應(yīng)用,千萬不要認(rèn)為ChatGPT或者文心一言是大模型,它們是基于大模型的應(yīng)用。另外,也有一些做生態(tài)的公司,做端到端的解決方案。
我再講講生成式AI的應(yīng)用場景。生成式AI現(xiàn)在已經(jīng)能夠生成對(duì)話的文本,也可以寫代碼,生成圖像和視頻。可以確定的是,GPT-5是一個(gè)多模態(tài)的模型,多模態(tài)已經(jīng)不是什么新鮮事了,但GPT-5可能是多模態(tài)里面做得最好的。因?yàn)镺penAI已經(jīng)提前把Sora(OpenAI研發(fā)的文生視頻大模型)給放出來了,大家一下子就驚呆了。包括我也驚呆了,我不認(rèn)為那么早能做出這么好的文生視頻,結(jié)果它今年初就做出來了,非常驚人,所以我們跟他們是有代差的。從行業(yè)應(yīng)用來說,生成式AI可以用來開發(fā)小程序,節(jié)省效率,也可以應(yīng)用于消費(fèi)品、制藥、金融、娛樂、保險(xiǎn)等行業(yè)。從應(yīng)用場景來說,它可能涉及營銷、銷售、物流、客戶支持、法務(wù)、財(cái)務(wù)、人力資源等多個(gè)方面。在任何行業(yè)、任何企業(yè)的不同職能部門里面,我們都可以用到生成式AI。
提問環(huán)節(jié):
問:您剛才講到,屬于前大模型時(shí)代的早期AI技術(shù),現(xiàn)在還有一些應(yīng)用,比如說大模型的成本比較高,現(xiàn)在有些地方?jīng)]法部署。這部分傳統(tǒng)的AI技術(shù)在大模型時(shí)代還能存在嗎?還是說目前應(yīng)用這些技術(shù)的場景,以后都需要慢慢轉(zhuǎn)型,去使用大模型?
竇德景:我在咨詢公司時(shí)也經(jīng)常聽到類似的問題,值不值得花成本去訓(xùn)練大模型?我想對(duì)大多數(shù)企業(yè)來說,應(yīng)該不需要自己訓(xùn)練模型。比如千億參數(shù)的模型,大概需要至少幾百張顯卡甚至上千張顯卡,訓(xùn)練幾個(gè)月,才能訓(xùn)練出來,算力和時(shí)間成本很高。你就算不訓(xùn)練上億參數(shù)模型的話,你使用模型,也需要投入幾百萬元。
總結(jié)一下,如果一定要追求大模型的效果,你的投入可能暫時(shí)也低不到哪去。我們一般會(huì)給用戶算投資回報(bào)率(ROI),你投入了多少,最后產(chǎn)出了多少。我當(dāng)時(shí)參與過一個(gè)醫(yī)藥公司使用大模型培訓(xùn)醫(yī)藥代表的項(xiàng)目,他如果每年都推出新藥,這筆賬肯定是劃算的。但如果幾年就培訓(xùn)這么一次的話,真不見得要使用大模型。
問:傳統(tǒng)的AI技術(shù)供應(yīng)商要么去做大模型的微調(diào),保持自己服務(wù)客戶的能力,要么就會(huì)被市場淘汰了?
竇德景:傳統(tǒng)供應(yīng)商不能寄希望于一些出不起錢的公司,來繼續(xù)做他們的客戶,他一定要有這個(gè)能力。但有一點(diǎn)好處是,大模型其實(shí)還是比較好用的。如果他原來就是搞AI的公司,要轉(zhuǎn)型去做生成式AI,就是換塊牌子,這個(gè)能力其實(shí)還是很容易掌握的。訓(xùn)練或者微調(diào)、提示、加訓(xùn),我覺得都能做。我這一年多也接觸了一些小公司,他們轉(zhuǎn)型還是很快的。
問:想請(qǐng)您預(yù)判一下,GPT-5出來之后,會(huì)對(duì)現(xiàn)在的AI能力有多大程度的提升?現(xiàn)在的大模型有各種幻覺,有人覺得不好用,GPT-5會(huì)變得好用嗎?
竇德景:GPT-5的幻覺會(huì)減少,因?yàn)镚PT-4的幻覺已經(jīng)比GPT-3.5減少了,我前面說的姚明的例子就很明顯。但它絕對(duì)不是100%的準(zhǔn)確,這是第一點(diǎn)。第二點(diǎn),GPT-5肯定是多模態(tài)。第三點(diǎn),既然Sora現(xiàn)在放出的視頻都大概有一分鐘,GPT-5生成的視頻肯定會(huì)更長、更逼真。現(xiàn)在Sora畫的幾個(gè)樣本里面,可能挑選出的是比較好的,但是里面還有一些瑕疵,你可以找出它們不符合所謂的物理世界的地方。GPT-5真正出來以后,Sora視頻中出現(xiàn)的人的左右腿在行走中互換的問題,肯定會(huì)被解決。
問:想問下您個(gè)人選擇的問題,現(xiàn)在很多做AI的人都在國外,因?yàn)楦鷩獗龋瑖鴥?nèi)技術(shù)代差蠻大的,您為什么堅(jiān)持在國內(nèi)做?另外,您為什么選擇去北電數(shù)智這樣一家算力公司,是看到什么機(jī)會(huì)嗎?
竇德景:第一個(gè)問題其實(shí)比較簡單。我2019年回國時(shí),想的是不一定會(huì)留在中國。因?yàn)楫?dāng)時(shí)美國大學(xué)每六年有一個(gè)學(xué)術(shù)休假,在學(xué)術(shù)休假的時(shí)候,我應(yīng)該去哪都可以。我當(dāng)時(shí)計(jì)劃在百度待個(gè)半年一年就回學(xué)校了,結(jié)果因?yàn)榧彝サ雀鞣矫娴脑颍痛聛砹恕5竭@一次再選擇的時(shí)候,其實(shí)我今年3月去美國出差,還回了趟學(xué)校。他們肯定還是歡迎我回去的,但是如果我現(xiàn)在去美國的話,我在國內(nèi)三四年時(shí)間積累的一些合作伙伴和關(guān)系,基本上用不了。所以我的選擇更多還是基于現(xiàn)實(shí)考量。
第二個(gè)問題,北電數(shù)智有算力,我們可以用這些算力服務(wù)國內(nèi)的模型公司。他大概會(huì)有1000P—2000P(P指10的15次方)的算力。用英偉達(dá)的顯卡來比較,一張A100的顯卡,算力大概是零點(diǎn)一幾P,一臺(tái)有8張顯卡的服務(wù)器,大概是1P。所以1000P的算力是很大的,相當(dāng)于8000張A100顯卡。
而且我們做的另外一件事情,是把國內(nèi)的芯片拿來做適配,因?yàn)楹苊黠@現(xiàn)在國內(nèi)已經(jīng)買不到英偉達(dá)的顯卡了。所以我們一定要想辦法,幫助國內(nèi)還能用的芯片被使用起來。這些芯片來自華為、百度昆侖芯、摩爾線程、寒武紀(jì)等公司,我們拿它們和英偉達(dá)芯片一起工作。
以后我在復(fù)旦大學(xué)里面花的精力會(huì)更多一點(diǎn),做比較前沿的研究。在大數(shù)據(jù)時(shí)代,我其實(shí)還不是最看重第四個(gè)V(Veracity)。大模型出來以后,數(shù)據(jù)的準(zhǔn)確性、真實(shí)性是很大的一個(gè)問題,現(xiàn)在的大模型在我看來是不安全的。第一點(diǎn),大模型產(chǎn)生的一些信息,你要是完全不考慮真實(shí)性的話,會(huì)出問題。第二點(diǎn),我覺得大模型本身并不壞,大模型不會(huì)自己主動(dòng)地想去作惡,但總會(huì)有些壞人想利用大模型作惡。就像人類最早研究質(zhì)能方程,是希望用核能的辦法來產(chǎn)生更多的能量,產(chǎn)生核電。但是核武器出來以后,一旦恐怖分子拿到核武器,會(huì)是很大的一個(gè)問題。同樣,我覺得大模型以后的發(fā)展需要監(jiān)管,需要安全的控制措施。所以在回到學(xué)校以后,我會(huì)更關(guān)注大模型安全方面的問題。
問:不考慮倫理的問題,人類能不能造出超強(qiáng)大腦?您預(yù)測多長時(shí)間可以造出超強(qiáng)大腦?
竇德景:先定義一下超強(qiáng),我理解你想表達(dá)的意思是比人還聰明。應(yīng)該說,目前大模型技術(shù)絕對(duì)是在往這個(gè)方向走。我覺得沒有任何理由說,以人的智力畫一條線,限制AI一定不能超過人。而且AI現(xiàn)在在很多方面已經(jīng)超過人,GPT-5可能也會(huì)在很多方面超過人。如果按照這個(gè)定義,人類已經(jīng)造出超強(qiáng)大腦了。
其實(shí)倫理方面的問題是什么?我們現(xiàn)在一定要想辦法,建立一套從上到下的機(jī)制或者是比較民間的機(jī)制,來限制AI作惡。我剛才已經(jīng)提到這個(gè)問題,我不認(rèn)為現(xiàn)在的AI會(huì)主動(dòng)作惡,AI還沒有自我意識(shí)。如果AI沒有自我意識(shí),它不會(huì)真的為自己謀霸權(quán)、謀利益。人類為什么會(huì)自私?人的自我意識(shí)是天生的。即使某一個(gè)人生下來了,他的基因里面沒有自我意識(shí),這種基因也很快就會(huì)失傳,因?yàn)樗畈幌氯サ摹K苑催^來說,現(xiàn)在的AI還沒有自我意識(shí),它不可能為自己謀利益、謀霸權(quán),但是怎樣防止有些壞人想通過AI來統(tǒng)治其他人或者統(tǒng)治世界,這個(gè)是我們要關(guān)心的事情。
問:超強(qiáng)大腦以后會(huì)有自我意識(shí)嗎?
竇德景:我現(xiàn)在看不出有辦法讓它有自我意識(shí)。我在幾個(gè)公眾場合都講過,這是我自己的一個(gè)理論,可以說是我首創(chuàng)的。我認(rèn)為,人為什么會(huì)有自我意識(shí),是因?yàn)槿松钤诘厍蛏希蛘哒f我們這些碳基生物生活在地球上,資源是有限的,如果你不去爭資源,你就活不下去,所以你天生就會(huì)有自我意識(shí)。或者說一開始有些人類、猿人是沒有自我意識(shí)的,有些有自我意識(shí),結(jié)果沒有自我意識(shí)的在過程中就被自然淘汰了。畢竟,碳基生物生活在一個(gè)資源有限的世界。
對(duì)硅基生物來說——假如我們認(rèn)為大模型已經(jīng)具備了生命或者生物的一個(gè)基本形態(tài)的話,至少我們沒有看到電能已經(jīng)少到讓一些機(jī)器人活著、另外的一些機(jī)器人就要死掉的狀態(tài)。但是,地球的資源還是有限制的。地球可能可以承載100億人,如果地球上的生物全變成硅基生物,地球肯定能承載200億個(gè)、300億個(gè)。假如地球上有1000億個(gè)硅基生命,我覺得不管水電、風(fēng)電、火電可能都不夠用了,那時(shí)候硅基生命就會(huì)打起來,就必須有自我意識(shí)了。
問:其實(shí)大模型出來的時(shí)候,有很多細(xì)分領(lǐng)域也在蹭這個(gè)熱點(diǎn)。比如在醫(yī)藥領(lǐng)域,當(dāng)時(shí)就有一些制藥公司說自己在做AI制藥,但也有觀點(diǎn)說其實(shí)他們用的技術(shù)不能叫大模型。我想知道這種垂直細(xì)分領(lǐng)域的模型,和大模型到底有什么不一樣?
竇德景:很簡單,就看它有沒有用大模型。因?yàn)榫退隳阌米钚〉拇竽P停热缜迦A的開源模型或者Llama開源模型(美國科技公司Meta研發(fā)的大模型),模型參數(shù)至少是60億到70億。理論上,英文單詞里面只有大語言模型(Large Language Model),沒有大模型。大模型這個(gè)概念,在英語單詞里面對(duì)應(yīng)的是基礎(chǔ)模型(Foundation Model)。但是我們還觀察到,如果模型參數(shù)小于幾十億,它的性能也不明顯。
特別是醫(yī)藥行業(yè)的公司,它不是簡單使用大模型的。因?yàn)楝F(xiàn)在這種公開的、要訓(xùn)練的基礎(chǔ)模型,它們拿到的這些跟醫(yī)藥相關(guān)的信息,都是從網(wǎng)絡(luò)上公開抓取的,相對(duì)來說都不專業(yè)。這些信息對(duì)特定的醫(yī)藥應(yīng)用基本上沒有用,你必須用你自己的專業(yè)數(shù)據(jù)來做微調(diào)或者二次訓(xùn)練,這個(gè)成本就上去了。所以,你就看他是不是真正用自己的數(shù)據(jù)訓(xùn)練,他不把這個(gè)過程走完的話,不應(yīng)該說自己用的是大模型。
問:之前幾波AI浪潮,都是經(jīng)歷了高潮,又退潮了。這一波浪潮會(huì)是怎么樣的?因?yàn)閺?022年底OpenAI推出ChatGPT開始到現(xiàn)在,好像始終沒有找到一個(gè)明星級(jí)的應(yīng)用,能夠給人類的物理社會(huì)帶來巨大改變。我看到現(xiàn)在有經(jīng)濟(jì)學(xué)家說,它可能對(duì)全要素生產(chǎn)率沒有顯著提升。從您的觀察來看,這會(huì)是一個(gè)可能的情況嗎?如果始終找不到明星級(jí)的應(yīng)用,它會(huì)不會(huì)退潮?
竇德景:這是可能的,前兩波高潮也是這樣的。比如第一波,20世紀(jì)50年代—60年代,邏輯推理出來了,后來發(fā)現(xiàn)邏輯推理只能把一些確定的信息給推理出來。第二波,貝葉斯、專家系統(tǒng)、淺層神經(jīng)網(wǎng)絡(luò)都出來了,最終都沒有找到殺手級(jí)應(yīng)用程序(Killer App)。
但是這一波浪潮,應(yīng)該是在三波AI浪潮里面最有可能成功。我媽媽79歲了,雖然她也是重點(diǎn)大學(xué)畢業(yè)的,但是她以前一直做儀表那塊的東西,可以說是AI的“門外漢”。她對(duì)我原來做什么都不是很關(guān)心的,結(jié)果她有一次問我,你知不知道ChatGPT?她都知道ChatGPT了,你說影響力有多大?這波AI浪潮造成的沖擊力,已經(jīng)擴(kuò)散到了計(jì)算機(jī)行業(yè)之外,它至少可以跟互聯(lián)網(wǎng)、iPhone相提并論,在我看來這波浪潮基本上是成功了。
只不過問題是,哪一個(gè)App可以先盈利?因?yàn)榇竽P统杀颈容^高,能不能賺到錢,其實(shí)是一個(gè)ROI的問題。但總會(huì)有一個(gè)特定的應(yīng)用出現(xiàn),因?yàn)殚_源模型本身就不收費(fèi),閉源模型也會(huì)越來越便宜,我覺得最后閉源模型都可以免費(fèi)給你用,通過這種手段來拉客戶,就像當(dāng)年的互聯(lián)網(wǎng)一樣。現(xiàn)在基本上大模型公司都在燒投資人的錢,有點(diǎn)跑馬圈地的感覺。但是總會(huì)剩下幾家擁有幾億用戶的公司,那他們總是能想辦法賺到錢的。
(經(jīng)濟(jì)觀察網(wǎng) 史額黎 整理)
 京公網(wǎng)安備 11010802028547號(hào)
京公網(wǎng)安備 11010802028547號(hào)
 購物車
購物車






